Designing 80:20 Rule Languages
EDIT: I made it clearer that the second language is not original.
If you calculate a running sum of the sorted frequency of every word in a long book 1, the result looks like the following curve:
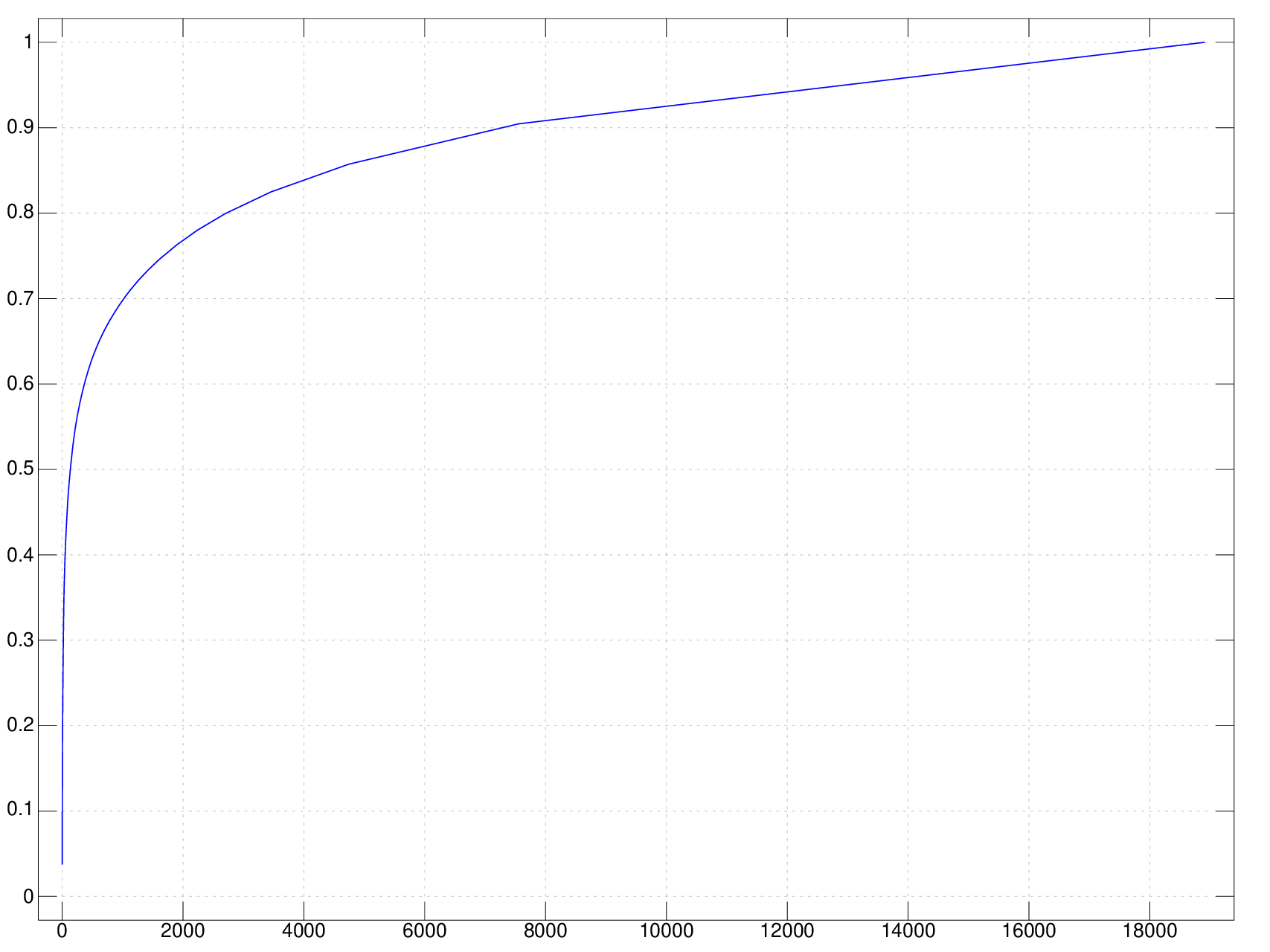
You can try this J program with your favorite book (as long as cutopen supports the language), where count is defined in my previous post: 2
NB. Plot the word count. Your text should only have one newline at the end of
NB. the file, otherwise `freadr` and `cutopen` won't work. J is definitely not
NB. an ideal language for string processing.
plot +/\ (% +/) \:~ (count"_ 0 ~.) cutopen , freadr 'your/book.txt'
NB. ~. finds the unique word
NB. (count"_ 0 ~.) is a monadic hook that gets the word count
NB. \:~ sort the word count
NB. (% +/) normalizes it
NB. +/\ calculate partial sumThere are 18000 kinds of words used in total, but only 20% of them is used in 80% of the scenarios. This phenomenon is known as the Pareto principle or the 80:20 rule. In this post, we will have some understanding about why this pattern appears, by designing two languages that follows the principle.
A Language With Equal Word Length
The first language is a boring one: every word has the same length.
The syntax of the first language:
- There is a finite set called alphabet.
- A word is an element of where is a fixed number.
- Characters in a word are iid samples of some random variable over .
For example, let , and the value of over is respectively, then a sentence of our language looks like:
aabaa bbbaa aabaa baaba abaca bbbba abaac ...
This can be generated using the following J sentence:
20 5 $ ((roulette"1) 100 3 $ 0.5 0.4 0.1) (({ >)"0) 100 $ < 'abc'Typical Set and the Asymptotic Equipartition Principle
We will focus on one seemingly arbitrary property of the language: the information content of a word. Let be the random variable that represents the information content. Given a character , we have
Since the characters are iid samples, according to the law of large numbers, for every : where is the entropy of .
Let be the set of words where the average information content is close to the entropy (it’s called the (weak) typical set in information theory). We know from the equation above that you will almost surely get an element of when sampling a word, despite that is relatively small as we will see.
To estimate , let’s consider an element and try to answer: What’s the probability of getting the word ?
Here we can make use of the iid assumption again:
By definition of ,
Therefore,
We know this is true for every , so the probability of is lower-bounded:
is a probability, therefore it can’t be greater than 1:
Then we have this nice upper bound of :
The result is a part of the asymptotic equipartition principle in information theory.
Making The Language 80:20
Let go back to our simple language, and find a set of parameters to make it satisfies the 80:20 rule.
The typical set will have less than 20% of the element if
We can use the probability distribution to ensure that the entropy is always less than 2 for every that has more than 1 element (see appendix A for the proof).
Setting and using the result , we got the first constraint
Unfortunately, weak LLN (1) doesn’t tell us how the probability converges as , and the simplest way I came up with is to sample a lot of words.
n =: 6
m =: 8
sample =: 100000
NB. We use the constraint above to get a valid epsilon.
eps =: (1 - (2 ^. 5) % 2 * n) - 0.01
NB. The probability distribution
p =: (2 ^ _1 - i. m - 1) , 2 ^ - m - 1
NB. The entropy
e =: entropy p
NB. Sample the words
words =: roulette"1 (sample, n, m) $ p
NB. Take the y-th element of the probability
NB. The `"0` at the end specifies that its rank is 0
take =: 3 : '{: 1 {. y }. p'"0
NB. Calculate their average information content
i =: (+/ % #)"1 - 2 ^. take words
NB. (+/ % #) is a fork that calculates the averave
NB. Get the result
(+/ % #) (i < e + eps) *. (i > e - eps)The probability is about 0.84, so the configuration does give us a language that satisfy the 80:20 rule.
Another Language
I was about to end this post when I read this paper by Conrad and Mitzenmacher. The paper describes a way to generate languages where the length of words are varied and the word count is power-law distribution. Let’s have a look at a simple language described in the paper.
The syntax of the second language:
- There are only three kinds of characters: and spaces.
- Each character are iid samples from a probability distribution where and .
- A word is a sequence of s and s that are not separated by a space.
Again, let’s generate some sample texts with J:
p =: 0.5
((roulette"1) 100 3 $ p,(p * p),(1 - p * p)) (({ >)"0) 100 $ < 'ab 'The result looks like:
b ab baa ab baa aa ba bb ba aa baaaabbbbabb ba a aaba abaaaa
Note that there are some extra spaces in the text, but that doesn’t change the probability of word because of the iid assumption.
Zipf’s Law
Our second language is a much richer language: there are an infinitive number of words, and as a result, we can not say that a set of a words’ size is 20% of “the set of all words”. Instead, we will proof that the word frequency in our language (asymptotically) satisfies Zipf’s law.
Zipf’s law: Let the probability of the most frequent word in the language be , then where .
If we take the logarithm of , then we have
That’s why people usually describe Zipf’s law using straight lines in log-log diagram, like this one:
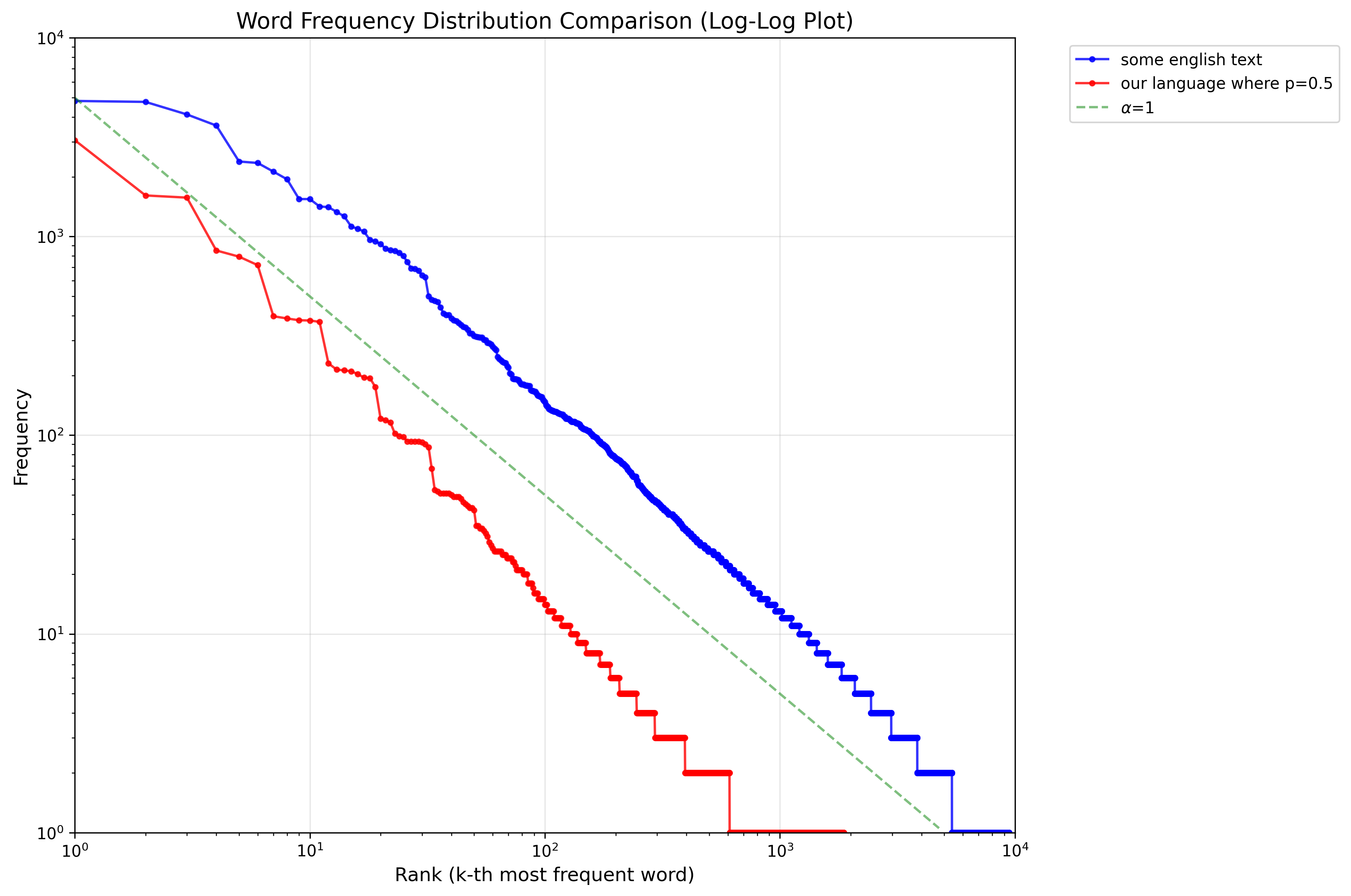 (this diagram is plotted using Python and the code is AI-generated, so I won’t paste it here.)
(this diagram is plotted using Python and the code is AI-generated, so I won’t paste it here.)
Frequency Ranking and Fibonacci Numbers
To know what the word is, we should sort all the words in our language according to its frequency. The probability of a word with s and s (and a space) appearing in a text is
We can generate the list of words ordered by their frequencies:
Every word can find its place in the list since every word’s probability has the form .
You may have noticed that the size of looks like the Fibonacci number (and I’m not sorting the words in alphabetical order). Indeed we can proof that , and thus (where ).
The proof. We can proof it by induction.
- and .
- Assume that and are and respectively. We prove that
where means concatenating the word with .
- Because every word in and has probability , therefore
- For a word , if it ends with , then we can strip away the last to get a word . It has probability , so it will appear in . Similarily, if ends with , then stripping away the last yields a word in . Therefore
One Last Trick
Finally, we can crack the problem of the frequency . If we can write as an expression of , then its probability is just times a constant.
Here’s the tricky part: we find that writing as a function of is harder than the other way, so we instead writing as a function of and take its inverse. We have and
Because , when is large, is close to 0, and the equation (3) becomes where are constant that we don’t care about, and is a relatively small value (in terms of ).
Then we have
Note that and , therefore the equation holds when is sufficiently large.
Conclusion
These two languages can’t fully explain the 80:20 pattern in natural languages, because we made an assumption that characters are iid, while characters in natural languages are not independent. For example, If you are asked to fill the blanks in t_ese t_ree words with one kind of character, you will choose h rather than e despite that the probability of e in English is higher than that of h. A better probabilistic model requires deep understanding of linguistics and better mathematical tools.
The concept of typical set and AEP are derived from chapter 4 of MacKay’s ITILA textbook. The first language is also influenced by its examples. Fixed-length words are widely used in computing, and typical set provides a way to compress them. In fact, the famous Shannon’s source coding theorem can be described as: we can compress our language without losing too much information, by only encoding the words in the typical set.
I have already mentioned that the second language is paraphrased from this paper by Conrad and Mitzenmacher. The paper proofs that the power-law distribution applies to languages with any probability distribution on a finite set of characters, not just on two characters.
Appendix: Why the Entropy is Always Less than 2
We want to prove that: for every ,
We can simplify to
The proof consists of two parts:
- increases monotonically,
- .
The first part is simple:
For the second part, consider the series (we can get this by taking the derivative of the series )
Let , then we have
Therefore
-
The book I used is Wuthering Heights by Emily Brontë, downloaded from the project Gutenberg. Actually, I found the plot hard to comprehend (probably because I’m often messed up with the names and don’t understand who is who) and gave up reading it. ↩
-
If there is a J verb that isn’t in the standard library and doesn’t have definition later in this post, then it’s defined in the previous post. ↩